<BookMark Up>
Prototipo di piattaforma online d'ausilio allo studio filologico

Opera di M. Bartolomeo Scappi, cuoco secreto di Papa Pio V (1570)
Affricate e sibilanti palatali davanti ad a, o, u
Affricate e sibilanti palatali davanti ad e
Affricata palatale sorda [tʃ] e [ttʃ] → (c)ce : eccettuando, luccetti, pasticcetti, un certo
→ scie: fascietto, lascieranno, pescie
Scempiamenti e geminazioni
Scrizioni latineggianti
Vocalismo
Consonantismo
e ‹-enza› (prudenza, esperienza, pazienza, avvertenza, diligenza, obbedienza)
e sui rispettivi ‹-antia› (sostantia)
‹-entia› (sufficientia, esperentia, diligentia, reverentia, preferentia, licentia)
Fenomeni generali
→ numerosi i casi di troncamento di e, i, o dopo r (esser, durar più di tre giorni, esser sodo)
TreeTagger: è uno strumento automatizzato che arricchisce il testo con informazioni linguistiche fondamentali. Per ogni parola, identifica la Parte del Discorso (POS) e la Lemmatizzazione, riducendola alla sua forma base.
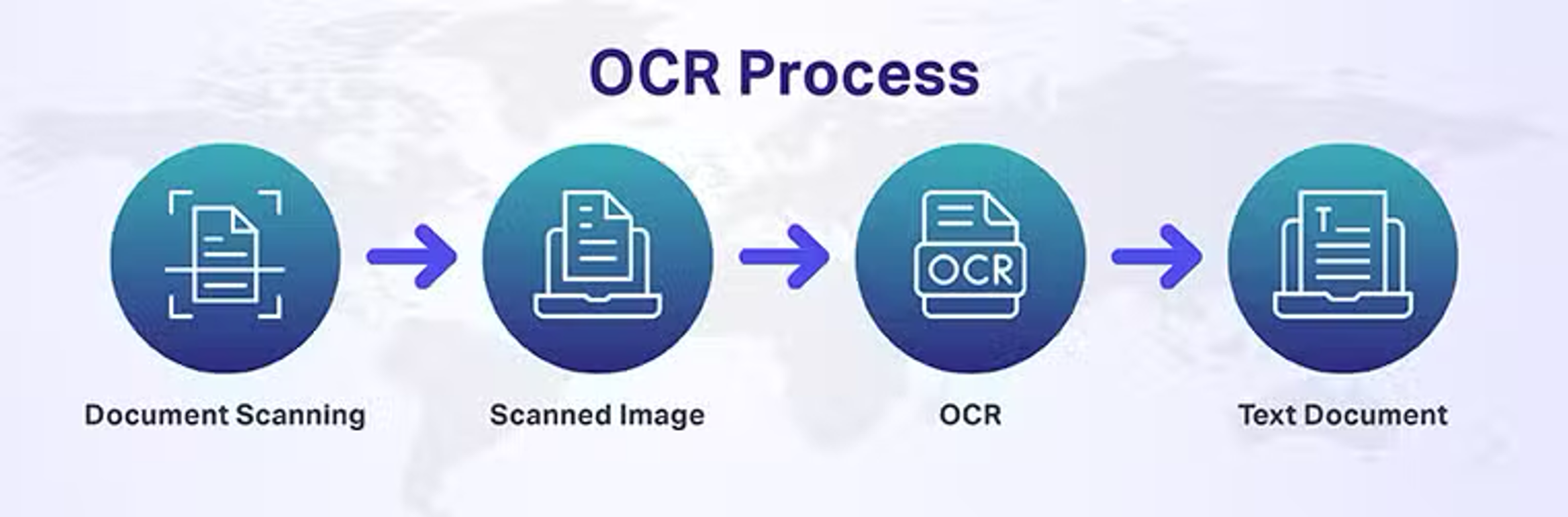
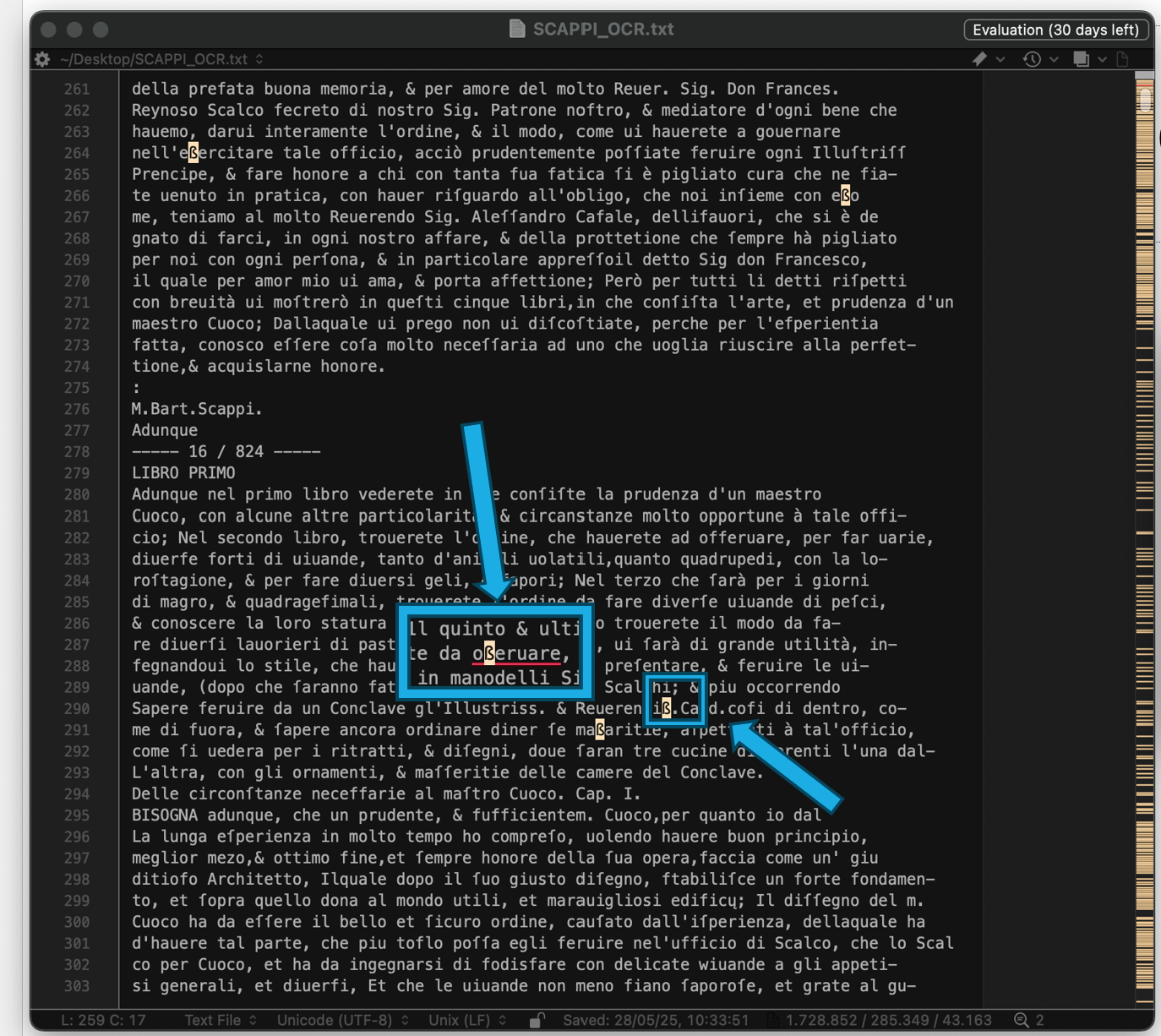
1) OCR (Optical CharacterRecognition): è una tecnologia che permette di convertire immagini di testo, come quelle provenienti da scansioni di documenti o fotografie, in testo modificabile e ricercabile. In pratica, trasforma un'immagine di testo in un formato leggibile dal computer.

2) Post-elaborazione OCR (Data Cleaning): rimozione del "rumore" di un testo, incoerenze e dati irrilevanti da un set di dati testuali.
3) Normalizzazione del testo e sostituzioni
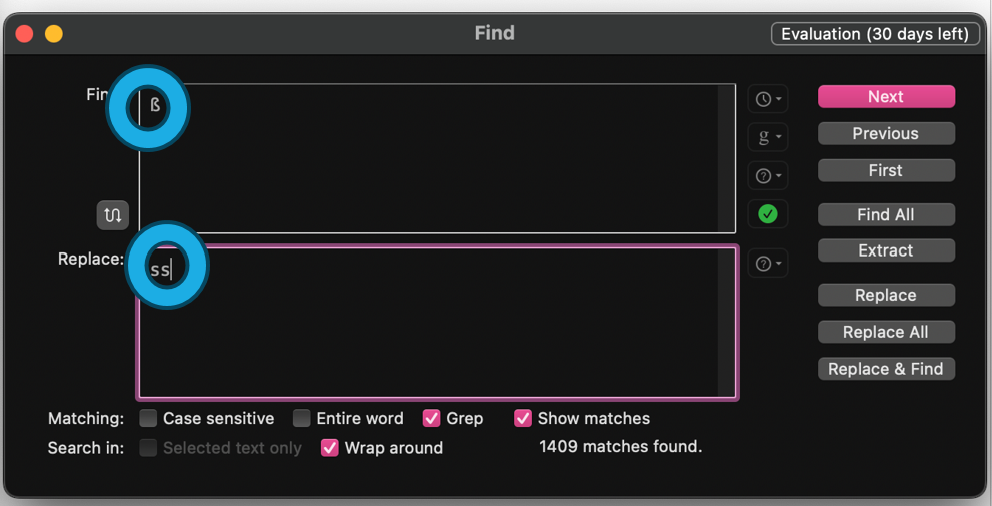
4) Applicazione di TreeTagger: utilizzo del parametro di italiano di Marco Baroni
(https://www.cis.uni-muenchen.de/~schmid/tools/TreeTagger/)
5) Esportazione del risultato in un file di output esterno direttamente dal terminale. È importante notare la presenza di tag 'unknown': TreeTagger si distingue per non fare ipotesi su lemmi sconosciuti, etichettandoli esplicitamente come tali.
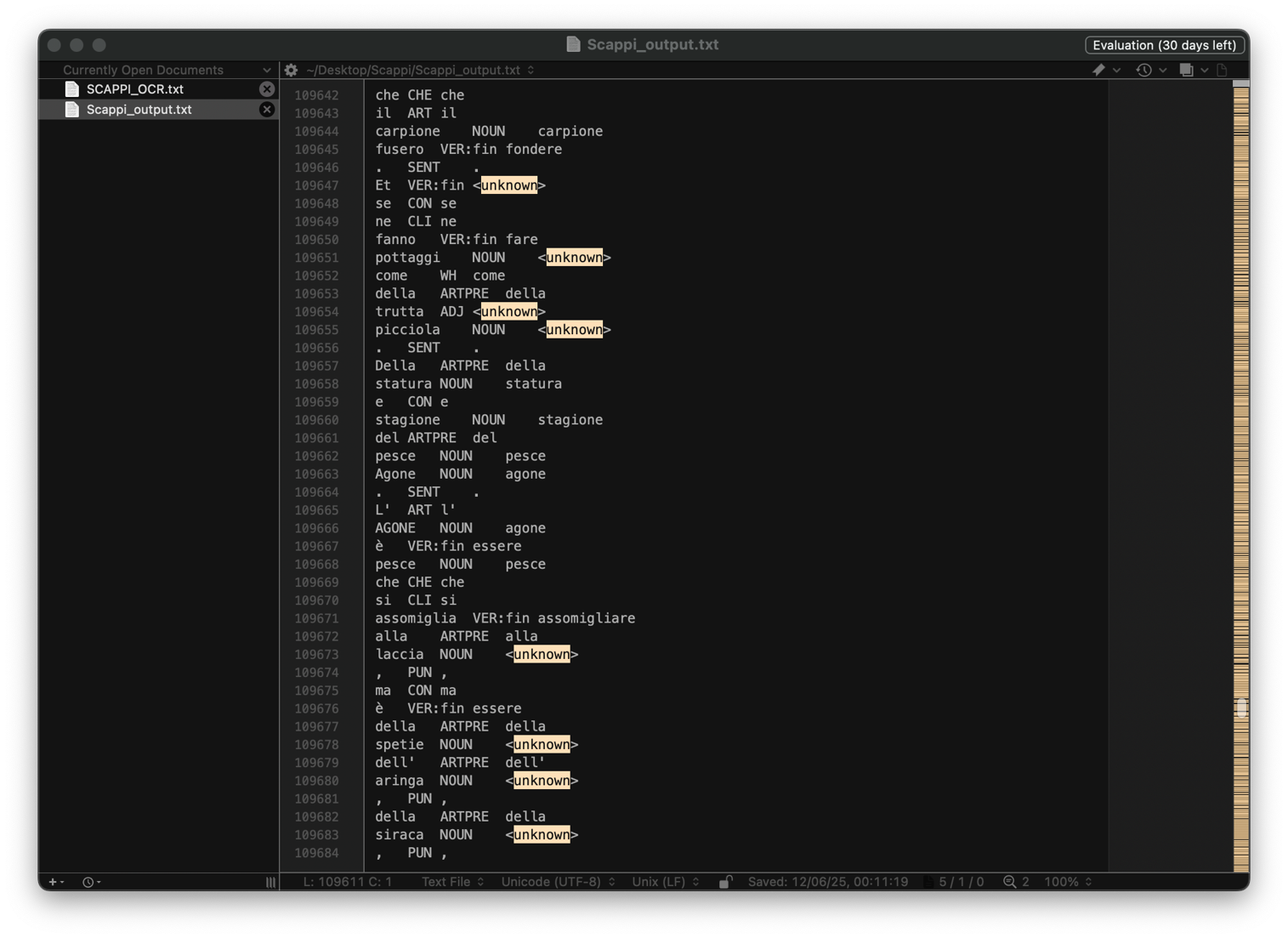
Sul testo di Scappi la percentuale degli unknown si classifica a 17.59%
(https://gite.lirmm.fr/advanse/sentiment-analysis webpage//tree/master/resources_on_server/TreeTagger)
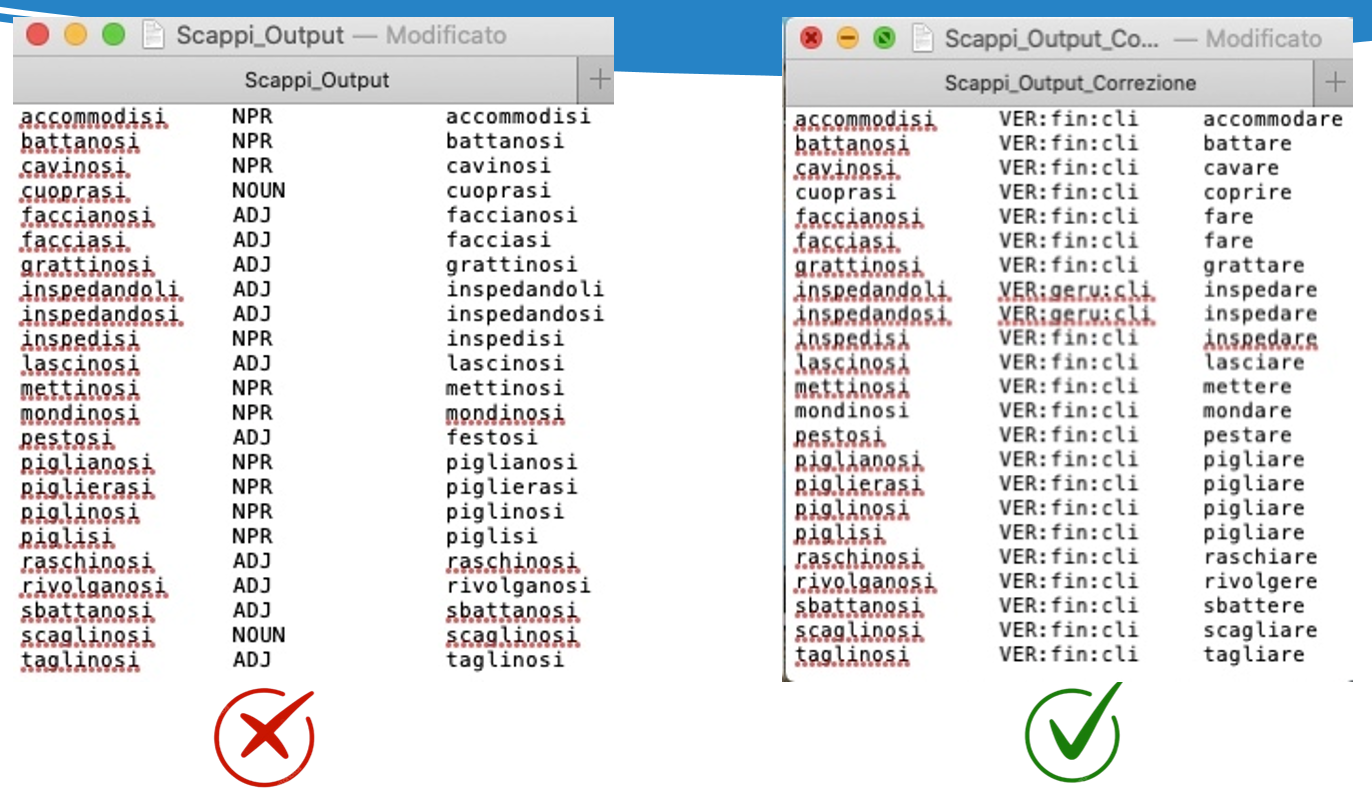
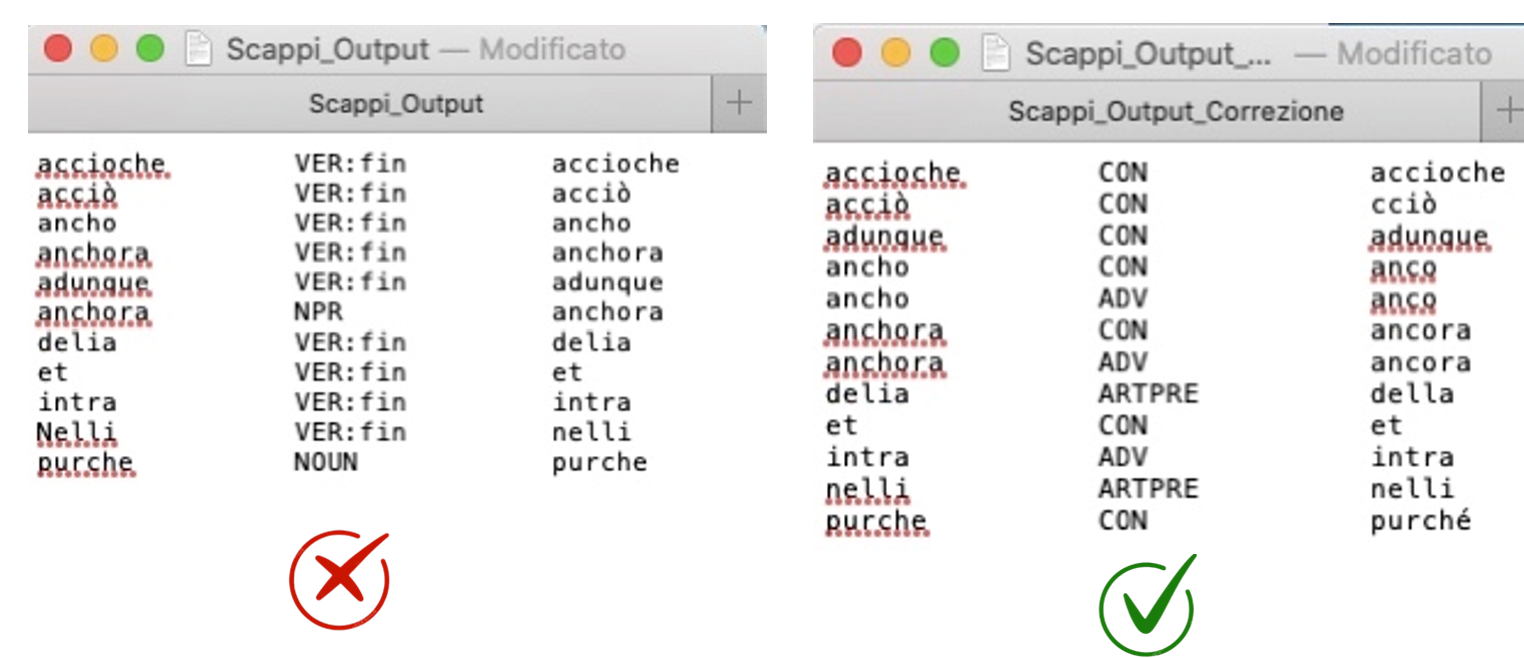
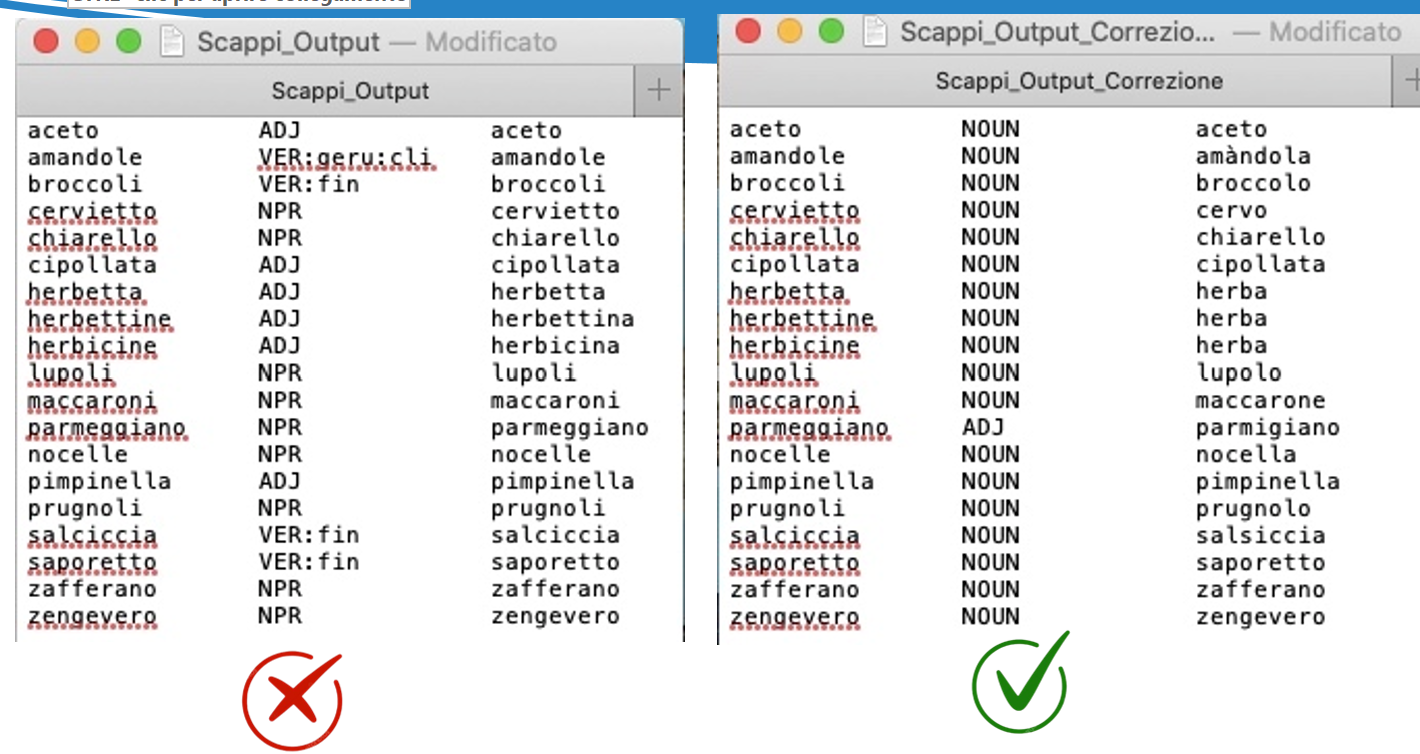
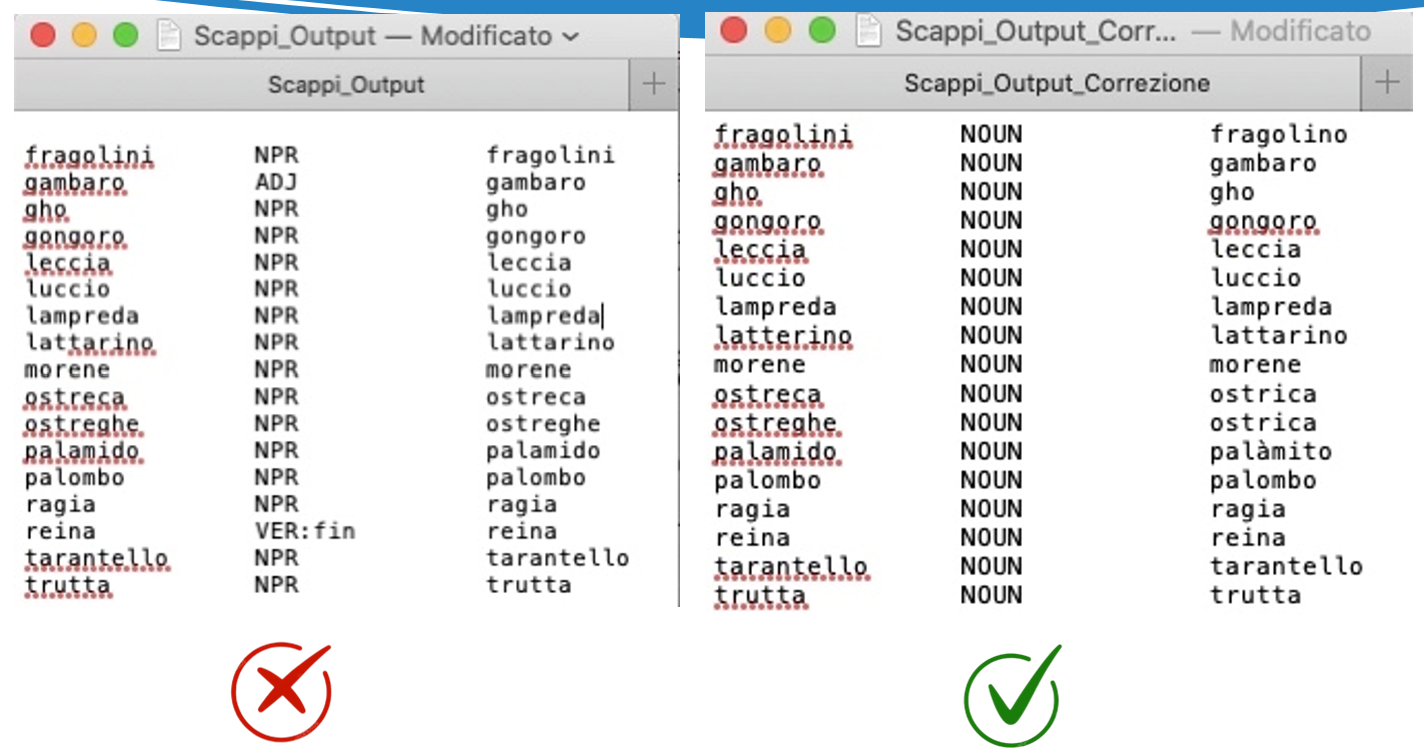
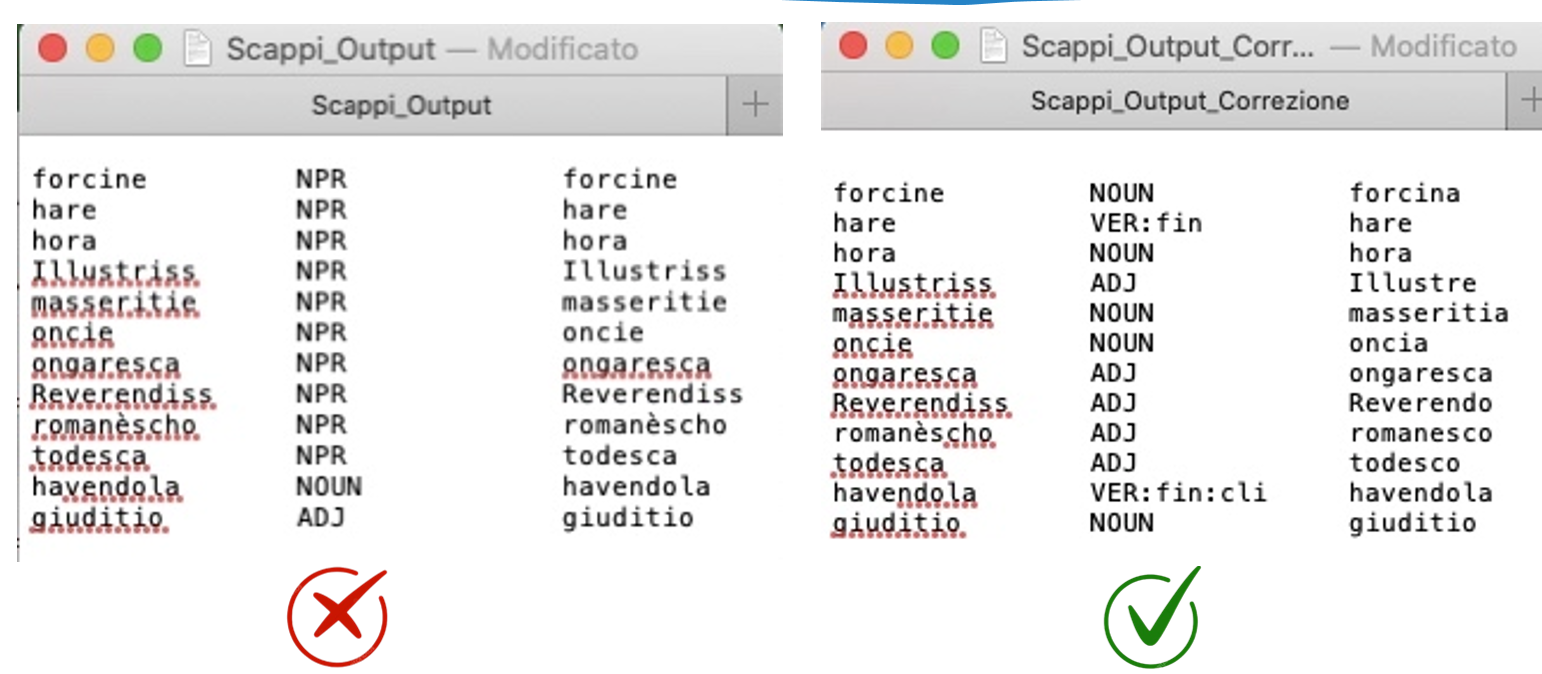
Il file .lex di TreeTagger è un lessico ausiliario che offre informazioni lessicali extra come la categoria grammaticale (POS tag) e il lemma delle parole. È cruciale perché riduce le parole "unknown": quando TreeTagger non riconosce un termine dal suo addestramento principale, cerca nel .lex. Se lo trova, gli assegna un tag e un lemma corretti, anziché etichettarlo come sconosciuto. Questo migliora significativamente l'accuratezza del riconoscimento.
8) Correzione manuale del file. lex con i relativi Tagset
Correzione effettuata tramite la consultazione delle risorse in formato digitale del Tesoro della lingua Italiana delle Origini (TLIO) e del Grande Dizionario della Lingua Italiana (GDLI), accessibili online.

9) Scelta di un testo «test»: la decisione del testo di riferimento per i test è ricaduta su Il Principe di Niccolò Machiavelli, in virtù della sua significativa vicinanza cronologica al testo in esame. Il processo di riconoscimento ottico dei caratteri (OCR) de Il Principe viene trattato analogamente a quello impiegato per il testo dello Scappi, prevedendo pertanto una rigorosa fase di post-elaborazione e normalizzazione testuale.

10) Applicazione di TreeTagger con lo stesso parametro utilizzato per lo Scappi e successiva lista di frequenza degli unknown: su Il Principe la percentuale degli unknown si classifica a 12.06%
11) Generazione di un nuovo parametro di TreeTagger per il volgare, S-PeachTreeTagger Volgare (S-PTV): viene creato un nuovo script che lancia TreeTagger-italian + l'opzione ".lex"

12) Il nuovo script viene lanciato su Il Principe, essendo definito come testo di test. Viene poi ricavata e confrontata la lista di frequenza degli unknown, notando come essa si sia ridotta drasticamente.
L’addestramento di TreeTagger sul modello del volgare conferma la possibilità di gestire le peculiarità delle lingue antiche.
